I was very fortunate to be invited to Stanford in April 2016 to talk about developments in the design of a database for Galileo’s library. What follows is a summary of my presentation with a few images. Many thanks again to Paula Findlen and Hannah Marcus for spurring me on with this work!
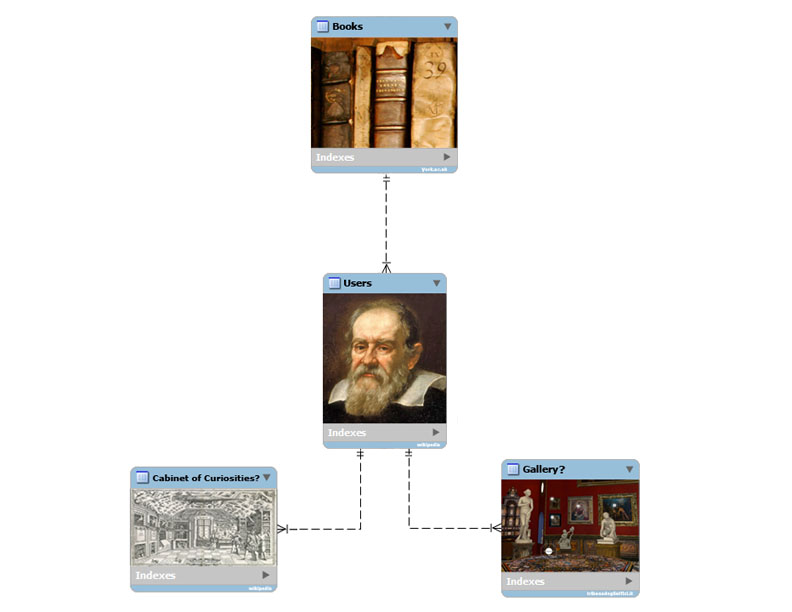
Visualization of the key components of a hypothetical database that reflects 17th-century use of books. With thanks to Jen Edwards for bringing it to life!
I am developing a database to serve as the foundation for an interactive web experience that uses Galileo Galilei’s library as its case study, but I arrive with great skepticism and great hope about how such a database could help us to better understand written culture, scientific practice, and literary inspiration in the early modern period. I hope to design the database as a research tool, not as a tool for presenting research materials. I take inspiration from John Wall’s Virtual Paul’s Cross project that seeks to recreate the experience of listening to John Donne’s Gunpowder Day Sermon in the courtyard of St. Paul’s. Through answering questions that arose during digital creation based upon two versions of the sermon and witness testimonies, Wall and his team have learned more about the composition of the sermon – the digital surrogate was a means to revealing something previously unknown about the historical artifact. It is a tool, not a surrogate; it creates knowledge rather than re-presents re-mediated content.
Great work in Digital Humanities, the history of book, and historiography has shown that this process rife with ethical issues. Interfaces organize and constrain (McGann). Cultural hierarchies drive selection criteria (Deridda, Bowker, McEwan). Boolean search of full text privileges preconceived ideas about content (Underwood). Ultimately I am looking for a way to model 17th-century sensitivities to book design and content. I want this tool to narrate for me in way that I, as a 21st-century scholar cannot, the categories, organizing principles, affinities, disparities, patterns, and outliers in the objects that I have collected.
I have described elsewhere the ways in which books in Galileo’s library challenge typically metadata analysis of publication year, content, or title. An example from the earliest work on the library very quickly demonstrates limitations of the subject index, which I see as a precursor to a relational table that could be used in a database:

Antonio Favaro’s organizational schema for the books in Galileo’s library (1884).
Antonio Favaro’s category of “Opere letterarie: Classici italiani/Literary works: Italian classics” shows just how complex the question can be. Galileo turned to Dante for characterization of his speaker Sagredo in the later dialogues, he sample from Petrarch for syntax, turned to Ariosto for provocative and pointed metaphors, and recited the verses of Francesco Berni for entertainment. Other readers would have turned to those same texts for other purposes. So genre would be an open category, use would contain ambiguities (and be missing significant information), and other metadata would be missing or misleading. I am not an archivist or a librarian; so by investing the time in creating this database I want to learn something that I didn’t already know about the relationships between my materials.
In part, I see the early modern period as one defined by the problems of classification brought about by what we now refer to as information overload. We could mention something as simple as things that move and things that are stationary in the night sky, but the problem extends to fields like botany (Ogilvie) or even the study of fossils (Sheehan). Is there a way to highlight some of the aspects of text that bring this dynamism (anxiety?) into relief for both a causal visitor to a site about early modern Italian books and for the specialized scholar?
Galileo provides two models: the princely gallery and the seemingly unorganized cabinet of curiosities. In order to build a database on these methodological principles, we might want to start by asking (as I did) about the model that Galileo preferred in order to make a first draft of features to document in the database: What textual features correspond to the ancient statues, sculptors, pictures, valuable stones, and high quality objects in the princely gallery? Canonicity and hierarchy can be measured by persistence through time and relationship to the source text. We could even use a resource like Naude’s description of libraries as a preliminary filter of what counts as authoritative or curated content for this gallery. Stylometrics highlight the most common features and clusters of similar documents. A search for commonplaces would show authors who were borrowing from the old tradition and could be analyzed in terms of frequency, persistence, and substance. Jerome McGann has suggested markup languages such as XML, which is adopted by the Text Encoding Initiative, as a way to highlight to access the pre-existing structures of text, and so by extension could highlight storage sites such as paratextual markers in headings, marginalia, and indices, but then also the coder-driven deep meaning of these texts. Even topic modeling would provide a more generative look at similarity and consistency over time.
At this moment in my research for the database design, a feeling of surprise hit: our current tools are very good at reproducing hierarchical, curated understandings of knowledge transmission. This was followed shortly upon by the fact that this means of evaluating early modern materials was not actually the mechanism that produced Galileo’s novel insights: it sounds like the Jesuits against whom he wrote. This is not what he articulated as a method of reading in his own works. The resolution of the competing apparent truths about the structure of the universe was not achieved through this kind of reading. This kind of representation doesn’t embrace the complexities of reading in the early modern period as we have been able to understand them.
Fortunately Galileo also provided the second model, the second space of collecting from his note, but expressed in a disparaging way because he so disliked the Gerusalemme liberata. Can the organization of this text-driven wunderkammer be useful for understanding signposts for early modern readers sensitive to these qualities in their texts? The system does not rely so much on pre-existing relationships as it does on a sense of exoticism, uniqueness, or rarity. The design would need to allow for relevance that is determined by apparent lack of relevance, or by inconsistency. The recent volume Taxonomies of Knowledge has also brought to light the ways in which the objects that resist classification – that create the rough edges to which Galileo reacts so harshly – are often the ones with the greatest potential to reveal tensions, inconsistencies, or previously unconsidered boundaries that the object is trying to inhabit. This is why so much of my work draws on genre theory.
If we want to explore the rhizomatic or fractal connections between cultural objects that Deleuze, Guattari, and Dimock propose, then we must do so outside the boundaries of inherited categorization practices. Dimock focuses on the marked, unique terms that aren’t frequent, but punctuate/puncture/or rupture readings. Relational tables start to break down under this pressure. The alternate structure should allow for the possibility of new categories and new patterns to emerge – to some extent we have seen this with Elizabeth Maddock Dillon and the Northeastern University team working on the Early Caribbean Digital Archive Slave Narrative project. The work of Ted Underwood, Michael Black, Loretta Auvil, and Boris Capitanu proposes one possible solution, which also addresses the possibility that genres change over time and that long-form texts are heterogeneous.One of the challenges of their approach is using publication date as a weight for the probability that a text reflects a given genre, but in early modern Italian and neoLatin texts, time seems to be less of a distinguishing feature of texts.
Finding the right mechanisms for revealing the relationships between the texts in Galileo’s library is at once about understanding the discovery of new knowledge, but also the emergence or existence of competing knowledge. By the time a possible formula is developed, hopefully the actions of searching and browsing will be collapsed so that the user of the project can experience these texts with a perspective not her own by encountering:
- a navigable structure that provokes inquiry
- something that allows for selection of a virtual book from this network
- reveals all of the ways that it nests within hierarchies or stands out against them
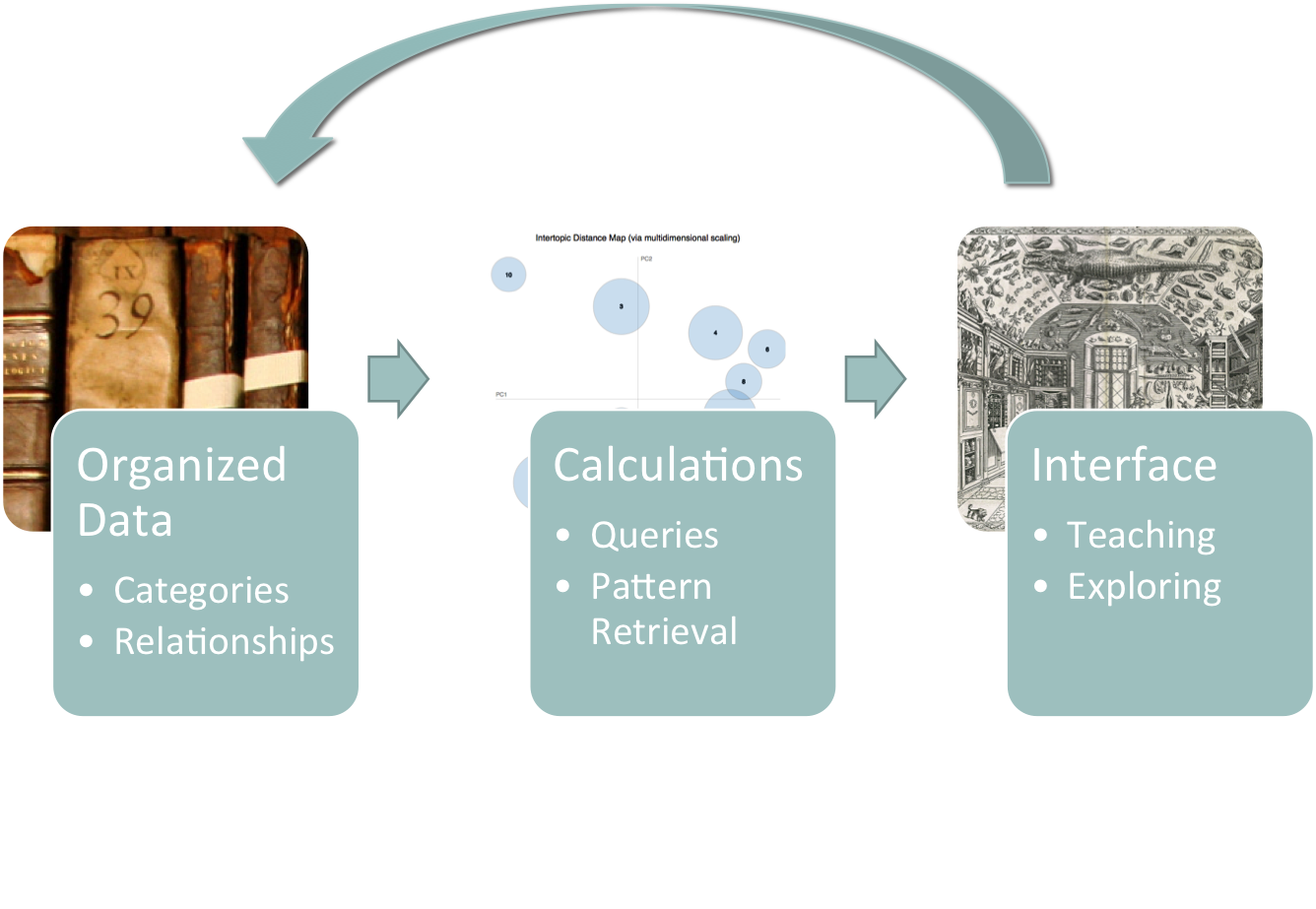
Visual representation of the interaction of layers in the Galileo’s library project.