lots more Vision profiling. For my parents’ information, that means that I found out what specific parts of the vision system slow the Aibo down. For the Aibo, ‘slow’ means that it can process less information in a second, or another way of putting it is that its reaction time degrades. Ideally, the Aibo will make decisions at about 30 times a second. Currently, with a bunch of stuff that we’ve been adding and some bottlenecks we’ve only just discovered, it’s down to about 23-25 frames per second (fps).
Moving onto more complicated things for fellow nBiters: over 50% of the average vision frame is taken up by chromatic distortion filtering. I know, it seems pretty ridiculous to me as well. About 25% percent of a vision frame is just thresholding, 7% is for line recognition, and then the rest is basically python processes including the EKF. Check the Wiki for more details.
Anyways, here are the areas for optimization:
-Chromatic Distortion (duh). We may be seriously screwing something up.
-Thresholding (duh). There may be more we can do here, either by reducing the size of the LUT or memory-wise.
-Python Overhead — see the tests on Trac, but I believe we’re losing about 3-4 fps just on creating python objects from c objects, a project ripe for Jeremy’s attention.
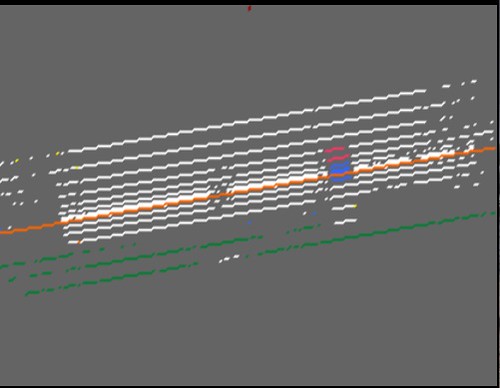
In other news, I found another huge bug in our body transforms just a few minutes ago: turns out I was doing body rotations in the wrong order (apparently matrix multiplication order matters, who knew?) and it took me re-reading and re-reading the German, Ozzie, and Texan papers to figure the proper order out. The focal point estimates look a lot better now in cortex and so I’ll be testing distance estimates tomorrow.
Next up: finally figuring out the pose-estimated horizon line swiftly followed by blob rotation fun. Fun.